NLP(2)- Transformer,BERT
데이터 사이언티스트가 알아야하는 NLP(2)- Transformer,BERT
Transfomer Model 이란?
Attention is all you need.
-
트랜스포머 모델은 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망이다.
-
트랜스포머 모델은 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망이다.
-
Attention 또는 Self-attention 이라 부리며 진화를 거듭하는 수학적 기법을 응용해 서로 떨어져 있는 데이터 요소들의 의미가 관계에따라 미묘하게 달라지는 부분까지 감지한다.
-
Google의 2017년 논문에 처음 등장한 트랜스포머는 지금까지 개발된 모델 중 가장 새롭고 강력하다고한다. ‘트랜스포머 AI’라 불리기도 하는 머신러닝계의 혁신을 주도학 있다.
-
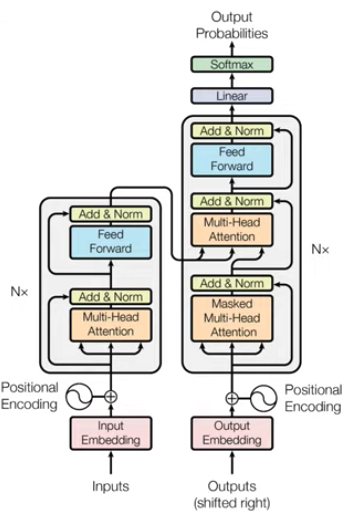
CNN,RNN을 전혀 필요로 하지 않고 attention만을 이용는데 이 떄, RNN과 같이 문장안의 각 단어의 순서 정보를 주기 어려운데 이를 Positional Encoding을 이용해 순서 정보를 준다.
-
Encoder와 Decoder로 구성되는 것은 동일하나 Attention 과정을 여러 layer에 반복 한다. 즉, Encoder가 N개 중첩된다.
-
RNN, LSTM 입력단어 갯수만큼 Encoder layer를 거쳐 hidden state를 만들지만, trans는 단어가 하나로 연결되어 병렬적으로 한번의 Encoder를 거쳐 병렬적으로 출력값을 생성함(계산 복잡도를 줄임.)
-
RNN은 순서대로 들어가기 때문에 state는 순서 정보를 가지고 있다. 이를 해결하기 위해 Positional Encoding을 Input Embedding Matrix와 element wise를 통해(더해줌) 구한다, 때문에 Positional Encoding 과 Input Embedding Matrix는 동일한 차원이여야한다.

-
인코더와 디코더라는 단위가 N개로 구성되는 구조이다. 그래서 Encoders(인코더들), Decoders(디코더들)이라고 부른다.
Transformer의 주요 hyper parameter
-
아래에서 정의한 수치값은 트랜스포머를 제안한 논문에서 사용한 것으로 사용자의 입맛에 따라 임의로 변경 가능.
-
dmodel = 512
-
트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기를 의미한다. 임베딩 벡터의 차원 또한 dmodel 이며, 각 인코더와 디코더가 다음 층의 인코더와 디코더로 값을 보낼때에도 이 차원을 유지한다.
-
num_layers = 6
-
트랜스포머에서 하나의 인코더와 디코더를 층으로 생각했을 때, 트랜스포머 모델에서 인코더와 디코더가 총 몇 층으로 구성되었는지를 의미한다. 논문에서는 인코더와 디코더를 각각 6층을 쌓았다.
-
num_heads = 8
-
트랜스포머에서는 어텐션을 사용할 떄, 1번 하는 것보다 여러개로 분할해서 병렬로 어텐션을 수행하고 결과값을 다시 하나로 합치는 방식을 택했다. 이 때 병령의 개수를 의미 한다.
-
dff = 2048
-
트랜스포머 내부에는 피드 포워드 신경망이 존재한다. 이떄 은닉층의 크기를 의미한다. 피드 포워드 신경망의 입력층과 출력층의 크기는 dmodel 이다.
BERT 란?
-
BERT(Bidirectional Encoder Representations from Transfomers, BERT)는 2018년 구글이 개발한 자연어 처리 신경망 구조이다. 기존의 단방향 자연어 처리 모델들의 단점을 보완한 양방향 자연어 처리 모델이다.
-
트랜스포머를 이용하여 구현되었으며, 방대한 양의 텍스트 데이터로 사전 훈련된 언어 모델이다.

출처: https://wikidocs.net/115055
→ BERT의 기본 구조는 위와 같이 Transfomer의 encoder를 쌓아올린 구조.
-
Base 버전에서는 총 12개를 쌓았으며, Large버전에서는 총 24개를 쌓았다. 그 외에도 Large버전은 Base버전보다 d_model의 크기나 Self Attention Heads의 수가 더 크다.
(트랜스포머 인코더 층의 수 L, d_model의 크기 D, Self Attention Heads의 수를 A라고 하였을때)
- BERT-Base : L=12, D=768, A=12 : 110M개의 파라미터
- BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
⇒ 초기 트랜스포머 모델이 L =6, D=512, A= 8이었다는 것과 비교하면 Base또한 초기 트랜스포머 모델보다는 큰 네트워크임을 알 수 있다.
BERT의 Contextual Embedding(문맥을 반영한 임베딩)
BERT는 ELMo 나 GPT-1과 마찬가지로 문맥을 반영한 임베딩을 사용함.

- BERT의 입력은 Embedding layer을 지난 임베딩 벡터들이다.
- d_model을 768차원으로 정의 하였으므로, 모든 단어들은 768차원의 임베딩 벡터가 되어 BERT의 입력으로 사용됨.
- 내부적인 연산을 거친 후, 동일하게 각 단어에 대해서 768차원의 벡터를 출력.
- 위 그림은 BERT가 각 768차원의 [CLS], I, love, you 라는 4개의 벡터를 입력 받아서(입력 임베딩) 동일하게 768차원의 4개의 벡터를 출력하는 모습(출력 임베딩)을 보여준다.

- BERT의 연산을 거친 후의 출력 임베딩은 문장의 문맥을 모두 참고한 문맥을 반영한 임베딩이 된다.

- 하나의 단어가 모든 단어를 참고하는 연산은 사실 BERT의 12개의 층에서 전부 이루어지는 연산이다. → 이를 12개의 층을 지난 후에 최종적으로 출력 임베딩을 언게 되는것
- 위의 그림은 BERT의 첫번째 층에 입력된 각 단어가 모든 단어를 참고한 후에 출력되는 과정을 화살표로 표현한 것인데 BERT의 첫번째 층의 출력 임베딩은 BERT의 두번째 층에서는 입력 임베딩이 된다.

- 셀프 어텐션, BERT는 기본적으로 트랜스포머 인코더를 12번 쌓은 것으로 내부적으로 각 층마다 멀티 헤드 셀프 어텐션과 포지션 와이드 피드 포워드 신경망을 수행하고 있다.
Position Embedding
- 트랜스포머에서는 Positional Encoding 이라는 방법을 통해서 단어의 위치 정보를 표현했다. 포지셔널 인코딩은 사인함수와 코사인 함수를 사용하여 위치에 따라 다른 값을 가지는 행렬을 만들어 이를 단어 벡터들과 더하는 방법이다.
- BERT에서는 이와 유사하지만, 위치 정보를 사인,코사인 함수로 만드는 것이 아닌 학습을 통해서 Position Embedding이라는 방법을 사용

- 위의 그림은 포지션 임베딩을 사용하는 방법을 보여준다.
- 위의 그림에서 WordPiece Embedding은 이미 알고있는 단어 임베딩으로 실질적인 입력으로 이 입력에 포지션 임베딩을 통해서 위치정보를 더해 주어야 한다.
- 포지션 임베딩은 위치 정보를 위한 임베딩 층(Embedding layer)을 하나 더 사용한다.
- 문장의 길이가 4 ⇒ 4개의 포지션 임베딩 벡터를 학습 ⇒ BERT의 입력마다 아래와 같이 포지션 임베딩 벡터를 더해준다.
- 첫번째 단어의 임베딩 벡터 + 0번 포지션 임베딩 벡터
- 두번째 단어의 임베딩 벡터 + 1번 포지션 임베딩 벡터
- 세번째 단어의 임베딩 벡터 + 2번 포지션 임베딩 벡터
- 네번째 단어의 임베딩 벡터 + 3번 포지션 임베딩 벡터
- 실제 BERT에서는 문장의 최대길이를 512로 하고 있어, 총 512개의 포지션 임베딩 벡터가 학습된다. → BERT에서는 총 두개의 임베딩 층이 사용된다. + BERT는 Segment Embedding이라는 1개의 임베딩 층을 더 사용한다.
BERT의 Pre-training

- ELMo는 정방향 LSTM과 역방향 LSTM을 각각 훈련시키는 방식의 양방향 언어 모델을
- GPT-1은 트랜스포머의 디코더를 이전 단어들로부터 다음 단어를 예측하는 방식의 단방향 언어 모델
- GPT와는 달리 BERT는 화살표가 양방향으로 뻗어 나가는 모습을 보여준다. 이는 마스크드 언어 모델(MLM)을 동해 양방향성을 얻었기 때문.
- BERT의 사전 훈련방법은 크게 두가지로 나뉨
- 첫번째는 마스크드 언어모델
- 두번째는 다음 문장 예측(NSP)
- BERT의 사전 훈련방법은 크게 두가지로 나뉨
Segment Embedding

- BERT는 세그먼트 임베딩이라는 또 다른 임베딩 층을 사용한다.
- 첫번째 문장에는 Sentence 0 임베딩, 두번째 문장에는 Sentence1임베딩을 더해주는 방식이며 임베딩 벡터는 두개만 사용.
- 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
BERT 파인튜닝
-
Single Text Classification

-
Tagging

-
텍스트의 쌍에 대한 분류 또는 회귀문제

-
질의 응답
