DistilBERT
huggingface DistilBERT
DistilBERT
- Distilling Knowledge 기법을 기존의 BERT model에 적용해 훨씬 작은 크기, 빠른 속도를 가지면서 비슷한 성능을 보인다.
- 이전의 knowledge distillation은 task-specific한 model (대개 supervised learning)에 적용되었다면, DistilBERT는 이를 BERT model의 pre-train(unsupervised learning)에 이를 적용했다.
- 그 결과 기존의 BERT model보다 40% 작은 크기를 가지면서 97%의 capability를 보존하고, 60% 빠른 model을 개발했다.
- 이 과정에서 language modeling, distillation, cosine-distance loss 3개의 loss를 결합해 사용했다고 한다….(무슨뜻이징…..)
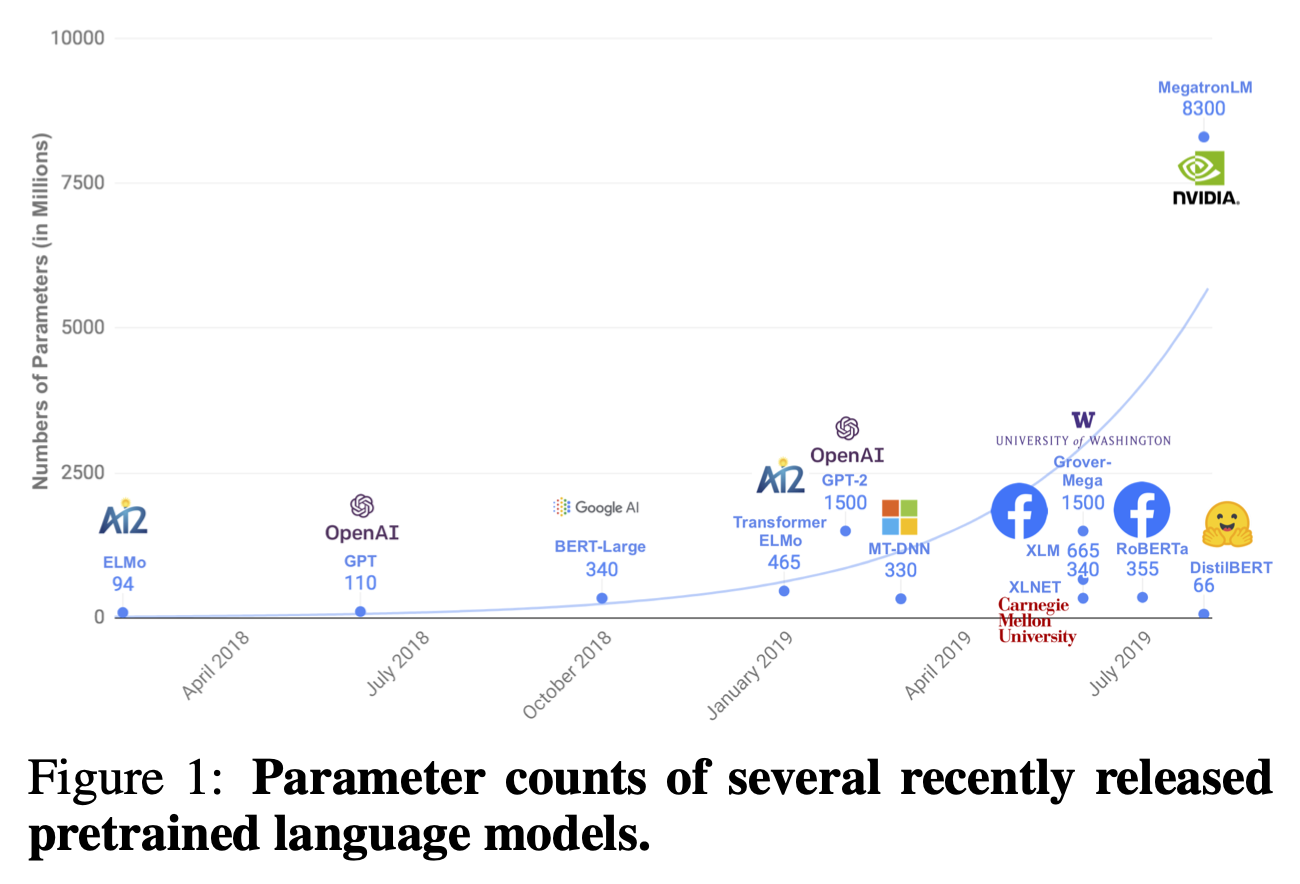
아직 내 실력이 논문을 이해할 정도가 아니라….완벽한 이해는 불가능하지만 일단 기존 BERT보다 가볍고 빠른 모델이라는 점….!
참고
[NLP 논문 리뷰] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter