NLP(1)- Seq2Seq with Attention
데이터 사이언티스트가 알아야하는 NLP(1)- Seq2Seq with Attention
딥러닝 기반 기계번역 발전 과정
RNN → LSTM → Seq2Seq (고정된 크기의 context vector 사용) → Attention → Transformer → GPT,BERT(입력 시퀀스 전체에서 정보를 추출하는 방향으로 발전)
GPT : Transformer Decoder Architecture 활용
BERT : Transformer Incoder Architecture 활용
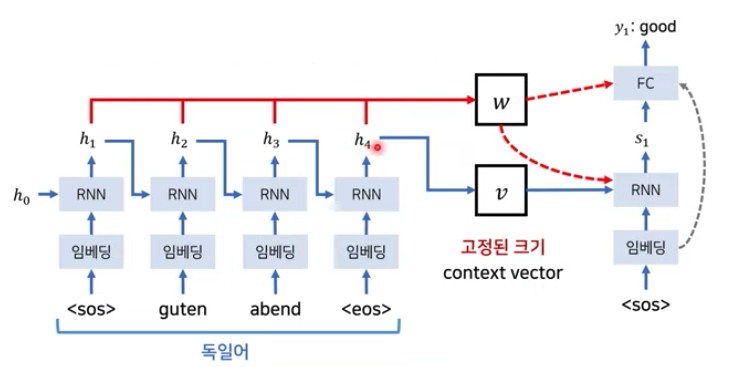
Seq2Seq Model
- Encoder
→ (sos(start of sentence)) quten abend (eos(end of sentence))
-
각 토큰은 embedding layer를 거쳐 RNN layer를 지나면서 각 layer의 출력값(h1,h2,…:activation function을 지난 후의 값)이 생기게 되며 이떄 각 출력값은 다음 layer의 input으로 들어가게 된다(RNN이기 떄문) 각 출력값(h1,h2…)는 고정된 크기의 context vector v에 모아지게 된다.
- Decoder
→ (sos(start of sentence)) good evening
-
Decoder의 layer도 마찬가지로 각 token이 embedding, RNN layer를 거쳐 출력값(s1,s2…)이 생성된다. context v는 첫번째 layer의 input으로 들어가게되고 s1으로 출력된다.
Seq2Seq Model의 문제점
-
context vector는 가장 마지막 layer의 output 값이다. Encoder의 소스 문장 전체의 문맥 정보를 포함하고 있으며 병목현상이 발생하고 성능 하락의 원인이 됨.
-
context vector를 Decoder의 첫번째 layer에만 반영하는 것이 아니라 Decoder 모든 layer에 입력으로 넣으면 성능이 조금 개선될 수 있으나, 소스 문장이 압축될때 정보가 손실되는 문제는 여전히 존재함.

Seq2Seq with Attention Model
-
기존 seq2seq는 인코더-디코더 모델로써, 단어가 가진 의미를 축약한 context vector를 인코더로 만들어내고, 그 의미에 부합되는 문장을 다시 해석해내는 역할을 수행했는데 이는 그 전까지 사용되던 단어 매칭 방식이나 문장 매칭 방식보다 훨씬 효과가 좋았다. 그러나 RNN Model의 고질적인 문제인, 오래 전에 나온 단어에대한 영향력 약화와 긴 단어, 매번 달라질 수 있는 단어의 길이를 고정된 길이의 context vector가 수용할 수 없다는 문제점이 존재했다.
-
그래서 여기에 Attention이라는 개념이 들어간다.

- Encoder 파트의 모든 rnn셀의 state 값을 활용하는 방식으로 attention weight을 통해 어떤 rnn셀의 state에 집중할지 결정하는 방식, context vector가 각각의 state별로 decoding 할때마다 달라진다. (크기 고정X)
-
seq2seq의 problem을 개선하기 위해 소스문장의 각 토큰이 연결된 모든 layer의 출력 전부를 입력으로 받음.
-
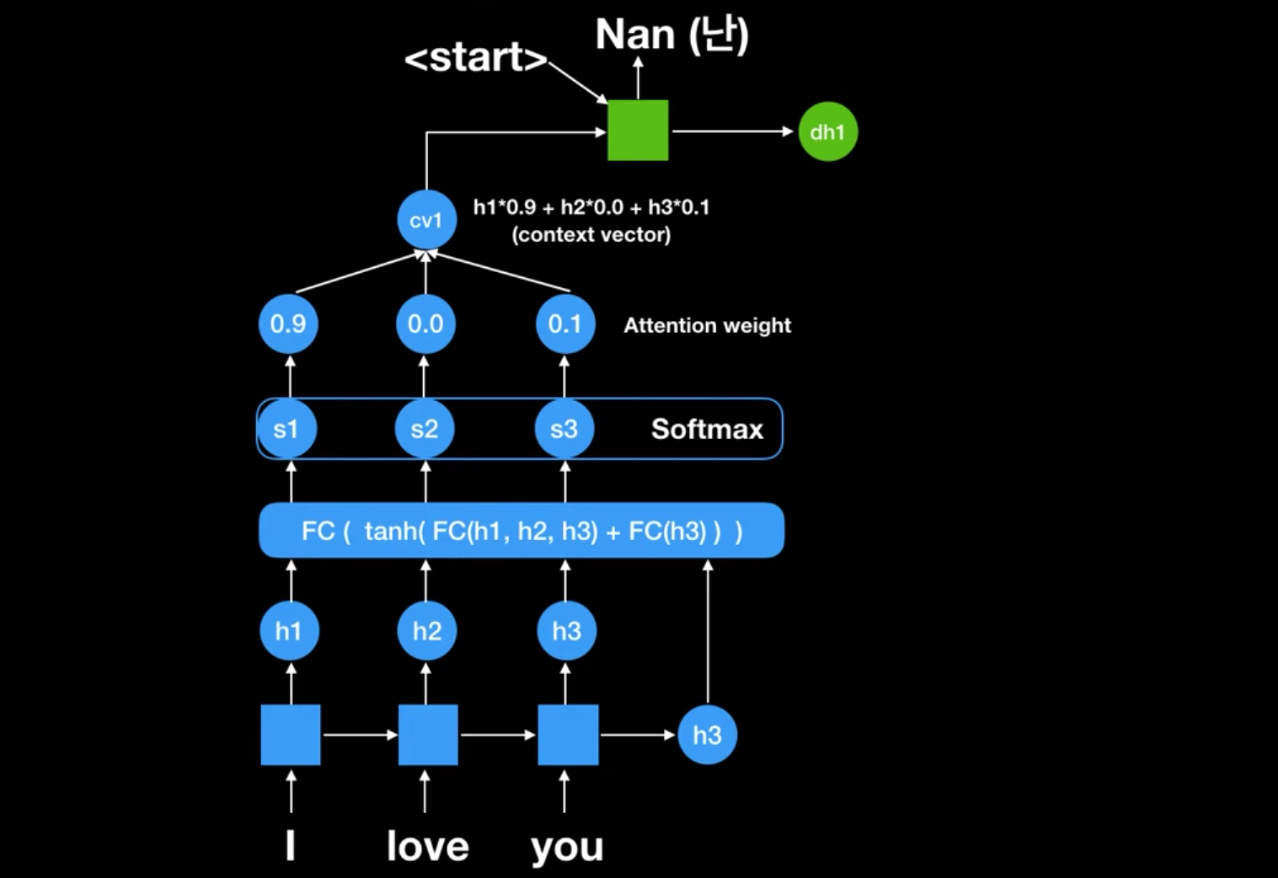
seq2seq 구조를 그대로 두고, h1+h2…(all hidden state values) = w(weighted sum vector)를 Decoder의 RNN Cell 과 FC의 입력으로 넣는것.
-
각 셀별로 나오는 state 값(h1,h2,h3) 와 seq2seq에서의 문맥벡터인 h3를 FC input 값으로 넣으면 이 값이 softmax에 넣어서 attention weight이 나온다. → 이 값이 첫번째 context vector인 cv1이 된다.(0.9h1 + 0.0h2 + 0.1h3) → cv1과 start vector를 받아서 NaN을 출력한다.

_i : 현재의 디코더가 처리 중인 인덱스 / j : 각각의 인코더 출력 인덱스 / ci : weighted sum
-
Energy : 매번 Decoder가 출력 단어를 만들 때마다 Encoder의 모든 출력을 고려하는 것, s는 Decoder가 Encoder 출력을 고혀하기 전 출력 값. eij = (어떤 h값과 가장 많은 연관성을 갖는지 수치화)
-
가중치 : 어떤 단어를 많이 참고하면 되는지를 적용 된 weight(예를 들어 h1=5%, h2=15% … (총 합)= 1 이되는 비율 값(softmax를 거친 값))
-
weighted sum : (Encoder의 각 출력값의 비율) * (가중치)의 합
-
weighted sum을 Decoder의 입력으로 넣어 줌, 즉 현재 Decoder 값과 가장 연관이 있는 Encoder의 출력값을 반영해 새로운 출력값을 뽑아내는 것.
-
attention weight(구해진 확률 값)을 이용해 각 출력이 어떠 입력 정보를 많이 참고했는지 알 수 있다.