EDA
데이터 사이언티스트가 알아야하는 EDA
What is EDA?
-
EDA(Exploratory Data Analysis, 탐색적 데이터 분석)는 벨연구소의 수학자 ‘존 튜키’ 가 개발한 데이터분석 과정에 대한 개념으로, 데이터를 분석하고 결과를 내는 과정에 있어서 지속적으로 해당 데이터에 대한 ‘탐색과 이해’를 기본으로 가져야한다는 것을 의미함
EDA와 데이터 시각화의 차이
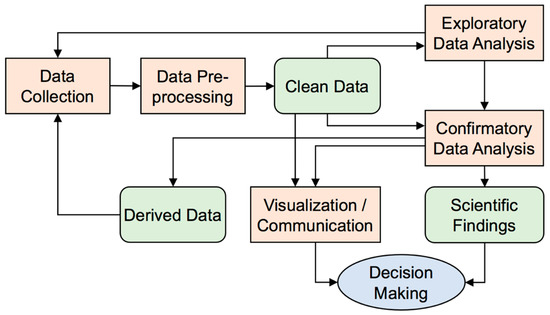
EDA → “Process of gaining relevant knowledge about a complex system”
Data visualization → “Process of telling what you learned and what you want to communicate”
EDA는 연구의 초기 혹은 데이터 정제(Clean Data) 이후 단계에서 이루어짐. 이 단계에서 얻은 이해는 알고리즘의 발전을 지원하고, 성능을 향상 시키는데 사용될 수 있음.
↔
데이터 시각화(Data Visualization) 는 분석 결과를 커뮤니케이션 하기 위해 연구의 마지막이자 의사 결정 전 단계(Decision making)에서 주로 행해지는 방법론
직접해본 EDA의 예)
직접 진행한 EDA과정 중 일부를 공개한다.
💡 digit 1/2/3 통계 정보와 이상치를 발라낼 수 있는 방법을 고민해보자
-
우선 입력이 없거나 결과코드가 이상한거 통계 숫자 뽑고 세부적인 EDA는 무엇을 해야할지 고민이 필요함
-
학습/검증/평가 데이터 분리하여 준비
💡 분석 결과를 어떻게 시각화 할지 기획하고 아이디어가 필요함
-
일단 노트북에서도 잘되는 matplot,seaborn 위주로 접근
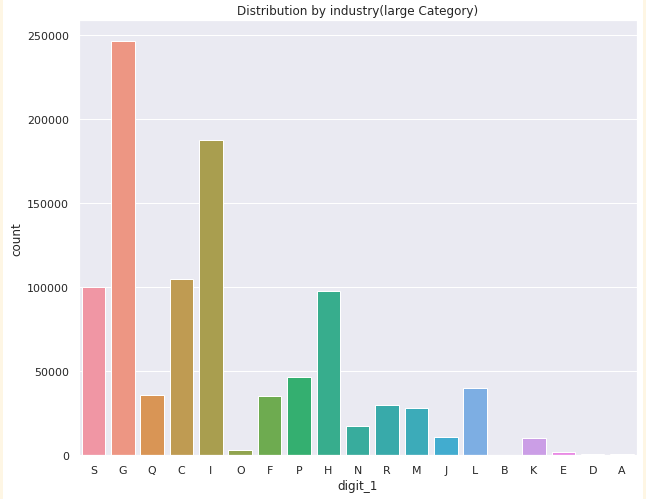
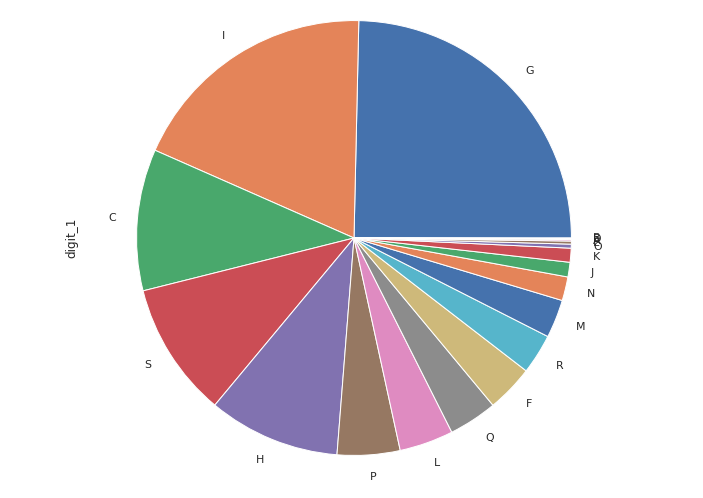
-
위 두 시각화 자료를 보아
G(도매 및 소매업) → 24.6472%
I (숙박 및 음식점업) → 18.7425% 의 순으로 데이터가 편향되어 있고
O (공공행정,국방 및 사회보장 행정) → 0.2965 %
E (수도,하수 및 폐기물 처리,원료 재생업) → 0.2255 %
A (농업,임업 및 어업) → 0.1064 %
D (전기,가스,증기 및 공기 조절 공급업) → 0.0756 %
B (광업) → 0.0424 % 순으로 데이터가 적다.
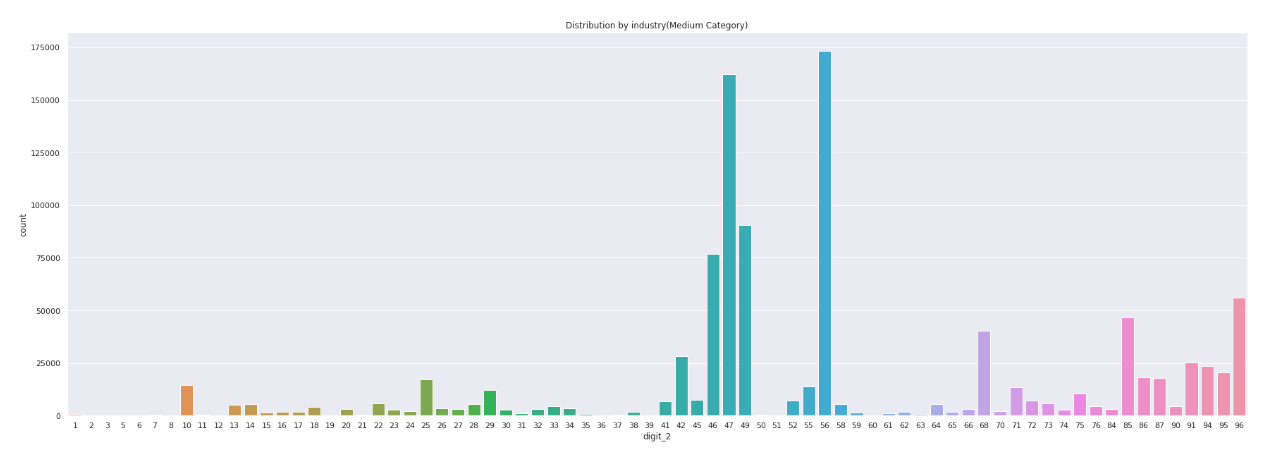
-
위 자료를 보면 A(01~03),B(05~08),D(35),E(36~39) 의 데이터 수가 현저히 적어 이 두 카테고리에 대한 추가학습데이터를 만들어야할 것으로 보임
-
데이터가 제일 많은 G(도매 및 소매업) 중에서 45(자동차 및 부품 판매업)에 대한 데이터가 현저히 적다
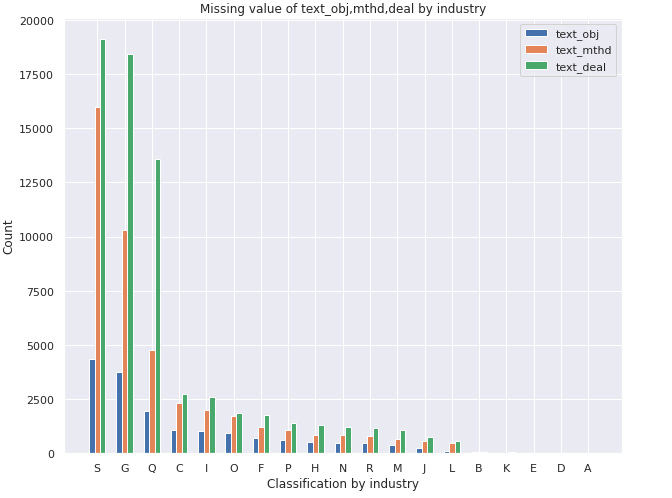
-
텍스트 데이터의 경우 text_deal (이 피처는 무엇을 거래하는지에대한 데이터로 추측됨)의 결측값이 다른 text_obj(장소), text_mthd(거래 대상,거래 방법)보다 많다.